laboratorio de arquitectura de computadores
IMPLEMENTACIÓN OPTIMIZADA DEL ALGORITMO CRIPTOGRÁFICO TEA
(tiny encription algorithm)

Autores: José Javier Soto Zúñiga
Javier
Sánchez Rodríguez
Introducción
El algoritmo TEA (Tiny Encription Algorithm) es uno de los algoritmos criptográficos simétricos más utilizados en la actualidad debido a su sencillez, robustez y facilidad de implementación. Es un cifrador de Feistel que usa operaciones entre grupos algebraicos ortogonales (sumas y XORs) de forma que se consigue un algoritmo muy resistente al criptoanálisis diferencial, tanto que de él no se conoce ninguna debilidad actualmente y se ha comparado en cuanto a seguridad al famoso algoritmo IDEA, aunque el TEA es mucho más simple y más rápido. Actualmente este algoritmo se emplea sobre todo en aparatos electrónicos que no dispongan de procesadores muy rápidos como teléfonos móviles, etc... y en programas informáticos que necesiten una alta velocidad de encriptación como servidores de IRC (el IRC-Hispano lo utiliza para cifrar las direcciones IP).
El TEA fue diseñado por Roger Needham y David Wheeler's, del departamento de informática de la universidad de Cambridge. Para más información se puede consultar la web http://vader.brad.ac.uk/tea/tea.shtml.
El objetivo de este trabajo es simular una implementación hardware de este algoritmo y optimizarla todo lo posible. Para ello utilizaremos 2 sumadores y una unidad de control diseñada especialmente para este caso.
Descripción del TEA
ANSI
C
void
encipher(const unsigned long *const v,unsigned long *const w,
const unsigned long * const k)
{
register unsigned long
y=v[0],z=v[1],sum=0,delta=0x9E3779B9,
a=k[0],b=k[1],c=k[2],d=k[3],n=32;
while(n-->0)
{
sum += delta;
y += (z << 4)+a ^ z+sum ^ (z >> 5)+b;
z += (y << 4)+c ^ y+sum ^ (y >> 5)+d;
}
w[0]=y; w[1]=z;
}
void
decipher(const unsigned long *const v,unsigned long *const w,
const unsigned long * const k)
{
register unsigned long y=v[0],z=v[1],sum=0xC6EF3720,
delta=0x9E3779B9,a=k[0],b=k[1],
c=k[2],d=k[3],n=32;
/*
sum = delta<<5, in general sum = delta * n */
while(n-->0)
{
z -= (y << 4)+c ^ y+sum ^ (y >> 5)+d;
y -= (z << 4)+a ^ z+sum
^ (z >> 5)+b;
sum -= delta;
}
w[0]=y; w[1]=z;
}
*
En estas 2 funciones, el cifrador y el descifrador, las variables z e y, de 32
bits, corresponden cada una a la mitad de la clave original de 64 bits, mientras
que a, b, c y d son los 128 bits de datos a cifrar o a descifrar, según sea el
caso. El número de interaciones n es igual a 32, aunque esto puede ser variable
ya que con sólo 6 iteraciones ya se consigue un nivel de seguridad muy
aceptable. En cuanto a delta, es una constante especialmente escogida para
aumentar la seguridad del algoritmo.
DESCOMPOSICIÓN
EN INSTRUCCIONES ELEMENTALES
A continuación presentamos la descomposición en instruccciones elementales que debe seguir nuestro procesador para realizar el algoritmo. Después está el mismo algoritmo escrito en un lenguaje de bajo nivel, en este caso ensamblador de la Máquina Rudimentaria, para que se pueda comparar el incremento de velocidad que se consigue con nuestro procesador respecto a un procesador no especializado como es en este caso el procesador de la Máquina Rudimentaria. Las instrucciones que pueden realizarse en el mismo ciclo de reloj están incluídas en el mismo bloque.
Nota: para los supuestos
prácticos de este trabajo hemos escogido valores arbitrarios para las
variables. Vamos a considerar que los valores iniciales de dichas variables
son: a=75, b=25, c=61, d=97, y=123, z=456, y que cada intrucción tarda un ciclo
de reloj en ejecutarse.
Codificador
(por pasos)
1 - a=75, b=25, c=61, d=97, y=123, z=456,
sum=0,delta=0x09E3779B9, n=32
/* Al disponer de registros separados y no de un banco de registros, se pueden escribir varios al mismo tiempo */
2 – n=n+(-1)
sum=sum+delta
si n=0
salta a fin
3 - tmp=(z<<4+a) xor (z+sum)
4 – tmp=(tmp+0) xor (z>>5+b)
5 – y=y+tmp
6 - tmp=(y<<4+c)
xor (y+sum)
7 - tmp=(tmp+0)
(xor) (y>>5+d)
8 - z=z+tmp
ir a paso 2 /* Esto en realidad no es una
instrucción pero la incluyo por claridad */
Número total de ciclos de reloj utilizados: 7*32+1=225 ciclos
Programa escrito en lenguaje ensamblador de la MR
1 ADDI R0, #75, R1
2 ADDI R0, #25, R2
3 ADDI R0, #61, R3
4 ADDI R0, #97, R4
5 ADDI R0, #123, R5
6 ADDI R0, #456, R6
7 ADD R0, R0, R7
8
ADDI R0, 0x09E3779B9, R8 /* Hasta aquí la inicialización de oper.*/
9 ADDI R0, #32, R9
10 SUBI R9, #1, R9
11 ADD R7, R8, R7
12 BRZ
13 ASL R6, R10
14 ASL R6, R10
15 ASL R6, R10
16 ASL R6, R10
17 ADD R10, R1, R10
18 ADD R6, R7, R11
19 XOR R10, R11, R10
21 ASR R6, R11
22 ASR R6, R11
23 ASR R6, R11
24 ASR R6, R11
25 ASR R6, R11
26 ADD R11, R2, R11
27 XOR R10, R11, R10
28 ADD R5, R10, R5
29 ASL R5, R10
30 ASL R5, R10
31 ASL R5, R10
32 ASL R5, R10
33 ADD R10, R3, R10
34 ADD R5, R7, R11
35 XOR R10, R11, R10
36 ASR R5, R11
37 ASR R5, R11
38 ASR R5, R11
39 ASR R5, R11
40 ASR R5, R11
41 ADD R11, R4, R11
42 XOR R10, R11, R10
43 ADD R6, R10, R6
Nota: las instrucciones ASL y XOR
no aparecen originalmente en el repertorio de instrucciones de la MR pero he
tenido que introducirlas para escribir el programa. Suponemos que utilizan el
mismo número de ciclos de reloj que el resto de instrucciones (4).
Número total de ciclos de reloj utilizados:
8+(35*4)*32=4488 ciclos
Rendimiento: 4488/225 . 100 = 1994 %
Nuestro
algoritmo es 1994 veces más rápido que el equivalente utilizando el procesador
de la MR
DISEÑO DE LA UNIDAD DE CONTROL
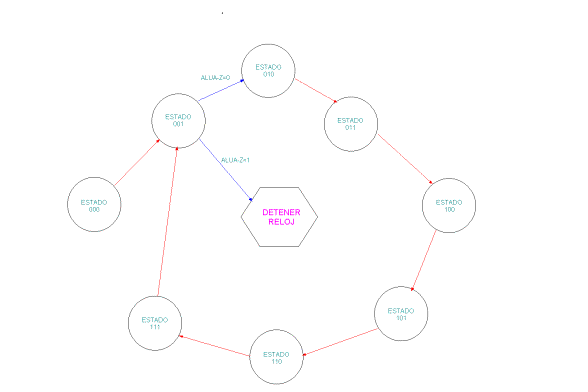
Diagrama
de estados:
Señales
que genera la UC: MUX1 (3 bits), MUX2 (3 bits), MUX3 (2 bits), MUX4 (1 bit), ALUA (2
bits), ALUB (2 bits), DMUX1 (1 bit), DMUX2 (2 bits), WR_MUNO, WR_A, WR_B, WR_C,
WR_D, WR_N, WR_Y, WR_Z, WR_DELTA, WR_SUM, WR_TMP.
Señales
de estado que entran a la UC: ALUA-Z (Indica cuando el resultado de una operación
aritmética en la ALU A es 0).
Señales
de Control a generar:
|
|
MUX1 |
MUX2 |
MUX3 |
MUX4 |
ALUA |
ALUB |
DMUX1 |
DMUX2 |
|
000 |
xxx |
xxx |
Xx |
x |
xx |
xx |
x |
x |
|
001 |
000 |
000 |
10 |
0 |
010 |
010 |
1 |
11 |
|
010 |
001 |
011 |
01 |
0 |
010 |
010 |
0 |
10 |
|
011 |
010 |
100 |
11 |
1 |
010 |
010 |
0 |
10 |
|
100 |
xxx |
xxx |
00 |
1 |
xxx |
010 |
x |
00 |
|
101 |
011 |
001 |
00 |
0 |
010 |
010 |
0 |
10 |
|
110 |
100 |
010 |
100 |
1 |
010 |
010 |
0 |
10 |
|
111 |
xxx |
xxx |
01 |
1 |
xxx |
010 |
x |
01 |
|
|
WR_MUNO |
WR_A |
WR_B |
WR_C |
WR_D |
WR_N |
WR_Y |
WR_Z |
|
000 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
001 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
|
010 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
011 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
100 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
|
101 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
110 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
111 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
|
WR_DELTA |
WR_SUM |
WR_TMP |
|
000 |
1 |
1 |
0 |
|
001 |
0 |
1 |
0 |
|
010 |
0 |
0 |
1 |
|
011 |
0 |
0 |
1 |
|
100 |
0 |
0 |
0 |
|
101 |
0 |
0 |
1 |
|
110 |
0 |
0 |
1 |
|
111 |
0 |
0 |
0 |
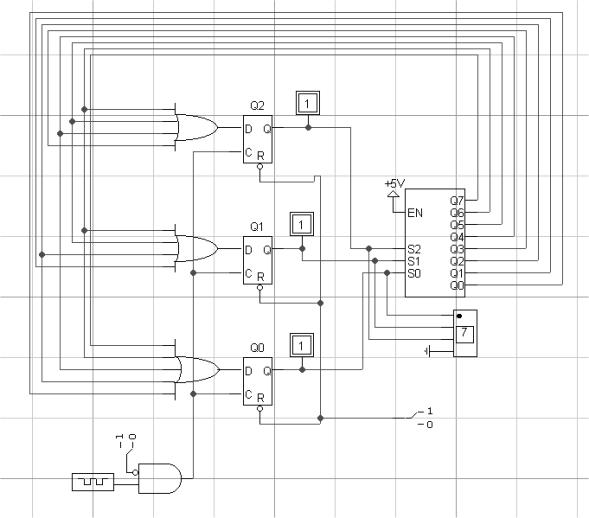
Implementación física de la UC
Para la implementación física hemos
decidido utilizar elementos de retardo debido a la sencillez y rapidez de este
tipo de circuitos y a que los contadores del simulador no disponen del modo de
“carga paralela”.
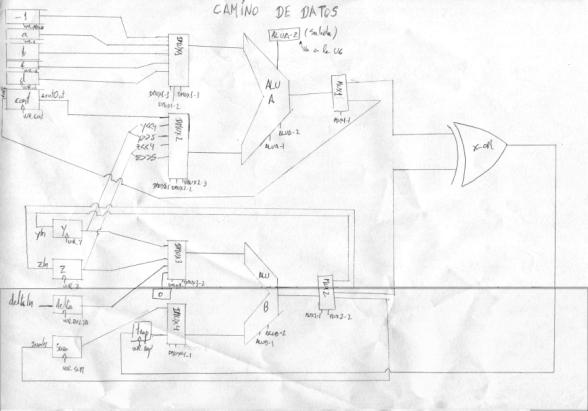
Camino de Datos